
Power BI Direct Lake with Microsoft Fabric
Direct lake mode connection, the optimal choice for analyzing very large datasets with frequent updates at the data source

In this blog post, I'm going to test the integration of Microsoft Fabric with Power BI using the Direct Lake connection.
I'll show you step-by-step how to use Microsoft Fabric to create a Lakehouse that will enable you to create a Direct Lake for Power BI reports.
Microsoft Fabric:
Microsoft Fabric is a new data platform that manages all stages of a BI chain. It is a single place where a BI project can be implemented from beginning to end, while eliminating the need to configure and manage multiple components and tools.
👇👇Take a look on my post:
🎊New 𝗠𝗶𝗰𝗿𝗼𝘀𝗼𝗳𝘁 𝗙𝗮𝗯𝗿𝗶𝗰 tool from the Microsoft Build 2023 announcement 🎊🎊

All data and all teams in one place that connects all data sources and analytics services in a single AI-powered platform, called Fabric. The new Microsoft Fabric is a box containing many products and services for building analytics projects. It includes 𝙙𝙖𝙩𝙖 𝙢𝙤𝙫𝙚𝙢𝙚𝙣𝙩 and 𝙞𝙣𝙩𝙚𝙜𝙧𝙖𝙩𝙞𝙤𝙣, 𝙙𝙖𝙩𝙖 𝙡𝙖𝙠𝙚, 𝙙𝙖𝙩𝙖 𝙚𝙣𝙜𝙞𝙣𝙚𝙚𝙧𝙞…
Power BI Direct Lake, comparing to Import and DirectQuery
With Direct Lake, it is not necessary to import the data into Power BI, instead Power BI will read the data directly from OneLake.

In power BI, we always have two modes of connection to data sources: Import mode, which provides a fast display and Direct Query mode, which provides fresh data.
We also have the composite mode but it requires an advanced level of expertise to set it up and manage it properly.
Import, DirectQuery, Direct Lake
Import mode, data is cached and optimized for Power BI queries without having to interrogate the data source for each DAX query submitted by a report.
➕➕Performance is better
➖➖ The Power BI engine must first copy the data into the dataset each time it is refreshed.
➖➖Any changes to the source are only taken into account the next time the dataset is refreshed.
Direct Query mode: The Power BI engine queries the data at the source,
➕➕Avoids copying the data
➕➕Any changes to the data source are immediately reflected in the query results.
➖➖This mode can be slow with sometimes poor performances
Today, Microsoft Fabric is proposing a new approach called Direct Lake, which allows to work in Direct Query mode on data stored in OneLake.
Direct Lake: combines the benefits of DirectQuery and Import modes while avoiding their inconveniences.
➕➕Performance is similar to Import mode, because data is loaded directly from OneLake with the facility to pick up any changes in the data source as they occur.
➕➕Contrary to DirectQuery, there is no translation to other query languages or query execution on other database systems, the data is already prepared on the Onelake.
==>Direct Lake mode can be the ideal choice for analyzing very large datasets and datasets with frequent updates to the data source.
To use Direct Lake, we need to create a Lakehouse in Fabric.
Create a Lakehouse in Fabric:
My goal is to create a Lakehouse in a workspace hosted on a supported Power BI or Microsoft Fabric capacity. The Lakehouse is a storage location for tables or files.
It will also be an access point to launch the Web modeling to create a Direct Lake dataset.
I opened Fabric and clicked on "Create"

I named my lakehouse

Once created, my Lakehouse is displayed as shown below.

In the Lakehouse explorer pane on the left we can find tables and files:
The Tables folder contains tables that we can query using SQL semantics. These tables are based on the open source Delta Lake file format.
The Files folder contains data files in the OneLake storage for the lakehouse that aren’t associated with managed delta tables. We can also create shortcuts in this folder to reference data that is stored externally.
Load Data in the Lakehouse
After creating a lakehouse, we can load data - in any common format - from various sources; including local files, databases, or APIs.
Data ingestion can also be automated using:
Data Factory Pipelines that copy data external sources
Data flows (Gen 2) that can be defined using Power Query Online
We can also create Fabric shortcuts to data in external sources, like Azure Data Lake Store Gen2.
In my case I will simply upload a file from my local computer.

Load data file into a table
In my case I need to load the data from the file into a table so that I can query it using SQL statements.

In the … menu for my loaded file, I select Load to Tables and then set the table name .

then I can see the underlying data in my table
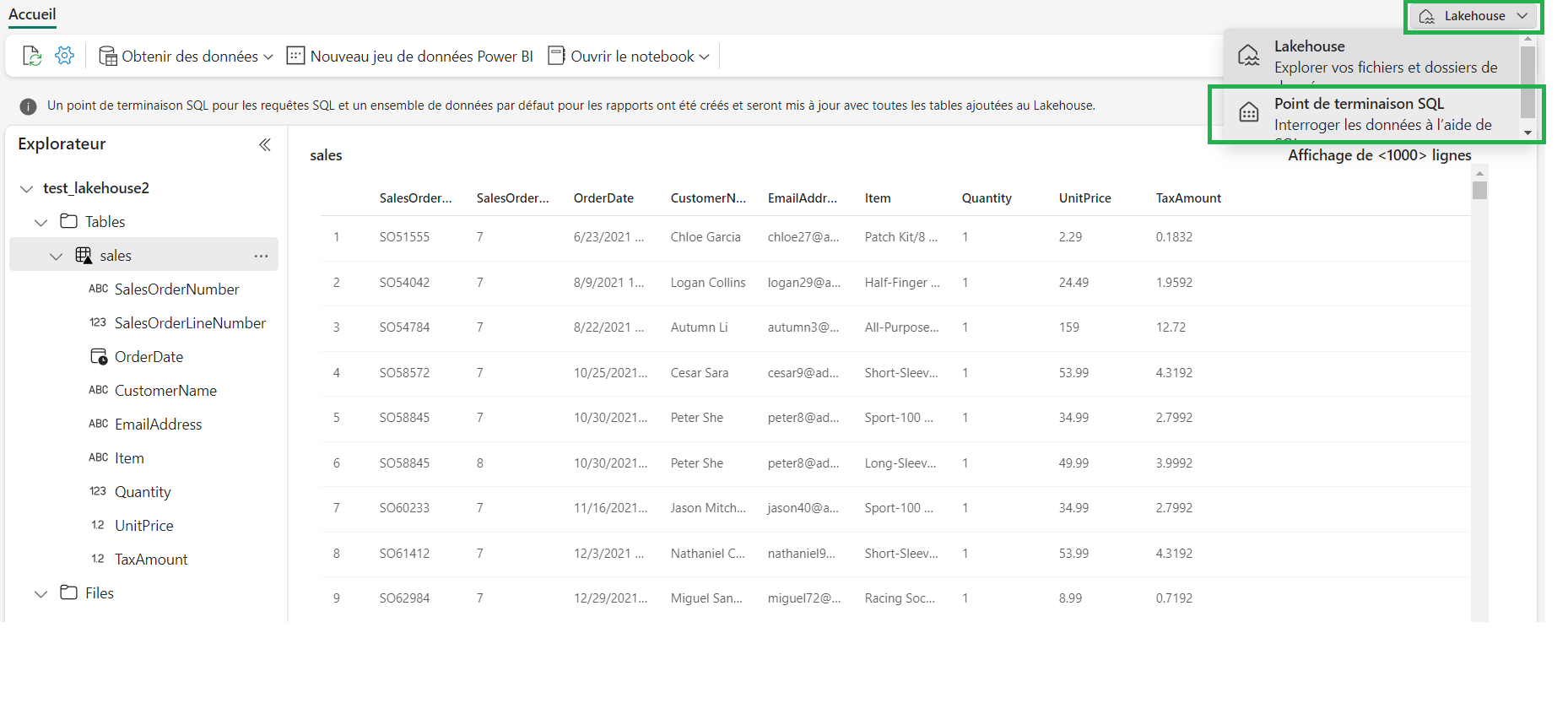
I can Use a SQL endpoint to query my table

👉Find how to create a lakhouse in this article
Configuring a Direct Lake Power BI Dataset
Here I will create my Direct Lake dataset directly from the table stored in my Lakehouse.
I selected the Lakehouse

In the Lakehouse, I clicked on "New Power BI Dataset", then I selected my table and clicked “Continue”

Then I can see my created dataset in my chosen workspace

Creating a Power BI Report from the created dataset
The next step was for me to create a Power BI Report.

On my dataset, I clicked on Create an “automatic report”
It generates for me a complete report connected with Direct Lake to the lakehouse.

I can then see the traceability of my report showing all the sources used to produce my report: from the SQL endpoint in the Lakehouse to the Power BI dataset, which is connected in Direct Lake mode offering fresh data and optimized performance.

Summary
Direct Lake mode is a revolutionary feature for analyzing large datasets in Power BI. Direct Lake is based on loading parquet-formatted files directly from a data lake eliminating the need to import or duplicate data in a Power BI dataset and also eliminating the need to query a Lakehouse endpoint.