
Hybrid tables dealing with other scenarios than time partition scenarios

Hybrid Tables:
Hybrid tables are large tables that have one or more partitions in Import mode and another partition in DirectQuery mode. This will make the refresh of huge tables faster with incremental refresh. Plus, it allows you to get the latest data in real time with DirectQuery.
I wrote a blog post about this great Power BI feature 👉Incremental refresh and real-time data for Power BI Premium datasets, with Hybrid tables
But if we're talking about hybrid tables, we're only thinking about incremental refresh scenarios where we take the most recent data and refresh it in real time using DirectQurey mode and store the historical data in import mode.
However, why do we limit ourselves to partitioning recent and historical data! The ability to create multiple partitions in one table, and to mix the storage modes of these partitions, offers a variety of possible implementations in different cases.
New scenario for using Hybrid Tables:
Inspired by Nikola's post, in this example I will detail how we can extend the hybrid table scenario to other use cases. In this use case test, I have to separate the sales with high demand products from the products with low demand.
According to the classification of my products "High", "Law" I will create two partions: one in Import mode for law products and the other in DirectQuery mode for high products in order to reflect the number of sales of these products in real time.

Hybrid table configuration:
Here is my model containing a NewSales fact table in import and a Product dimension table in Dual mode. My goal is to turn the Sales table into an Hybrid table.

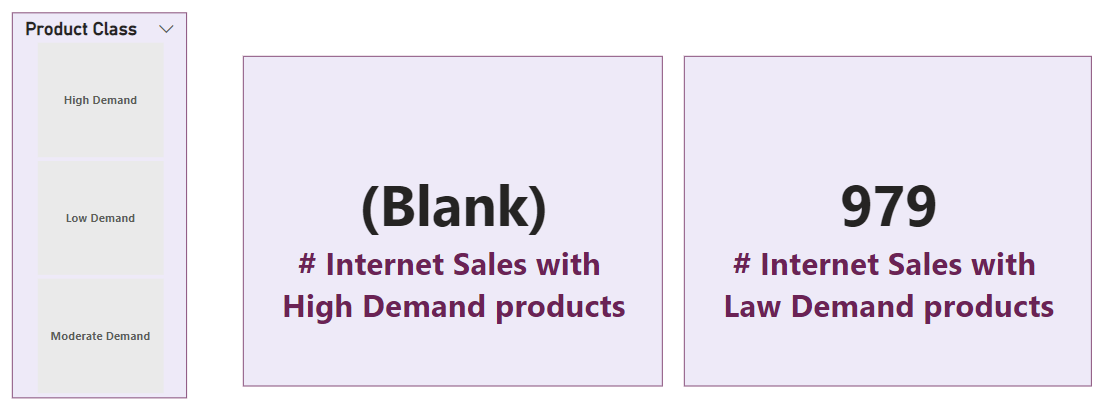
For that I filtered my NewSales table to only return sales of Law Demand Products, in order to create a default partition (in import) for these products.

So before starting I only have law products sales, which is shown through my two DAX measures:
Partions configuration in Tabular Editor:
Note that I published the dataset to Power BI premium capacity, and in this step I connected to it via the XMLA endpoint in Tabular Editor.
Here are the performed steps to create a second partition for High products, and set it in DirectQuery mode:
For the default partition: I renamed it to “ Sales Low Demand product Import”
For the new DirectQuery partition: I duplicated the first one, renamed it to “Sales High Demand Product DirectQuery”, changed its source SQL query to retrieve high demand products instead of low demand products and finally switched the storage mode of this partition to DirectQuery.


By applying the changes and refreshing the report I can see that my "high products" measure now returns a result:

Also my goal is to see the changes of these High products in real time.
To test this, I ran a query in a loop in my database that inserts new data every 2 seconds, and in order to reflect these changes in real time in my Power BI report I set up an "Auto page refresh" ==> the result is really great 😍my visuals are automatically refreshed in real time (no need to refresh the dataset)

Many thanks to Nikola from DATA MOZART for the inspiration of this article.